
I’ve been learning about Azure Managed Cassandra recently, and it’s very different from the usual relational SQL Server database. The documentation and tutorials can seem confusing at first, but once I broke things down it was easier to understand basic concepts.
I wrote this for others who are getting started with Cassandra.
A Quick Warning that Not All Cassandras Are the Same
If you’re using Azure Managed Cassandra, stick with Microsoft’s documentation. If you’re using DataStax, follow theirs.
The core concepts are similar, but the details can vary quite a bit. Mixing them up can come back to bite you later. I recommend reading the documentation that matches your specific setup. Always double-check that Azure Managed Cassandra supports everything you plan to use, like backup options, command availability, or modified Reaper settings.
No Master, No Problem
Let’s start simple.
In Azure, you start with a Region, which is geographical location in the world, like United States or Europe.
Each region contains multiple Availability Zones, which are separate, independent areas within the same region.
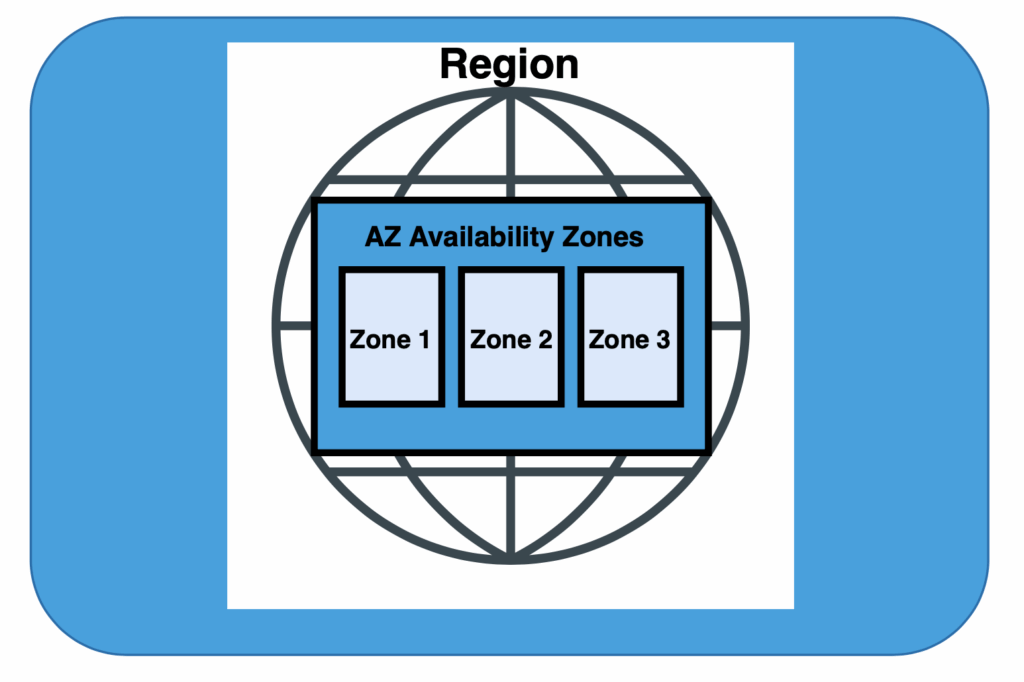
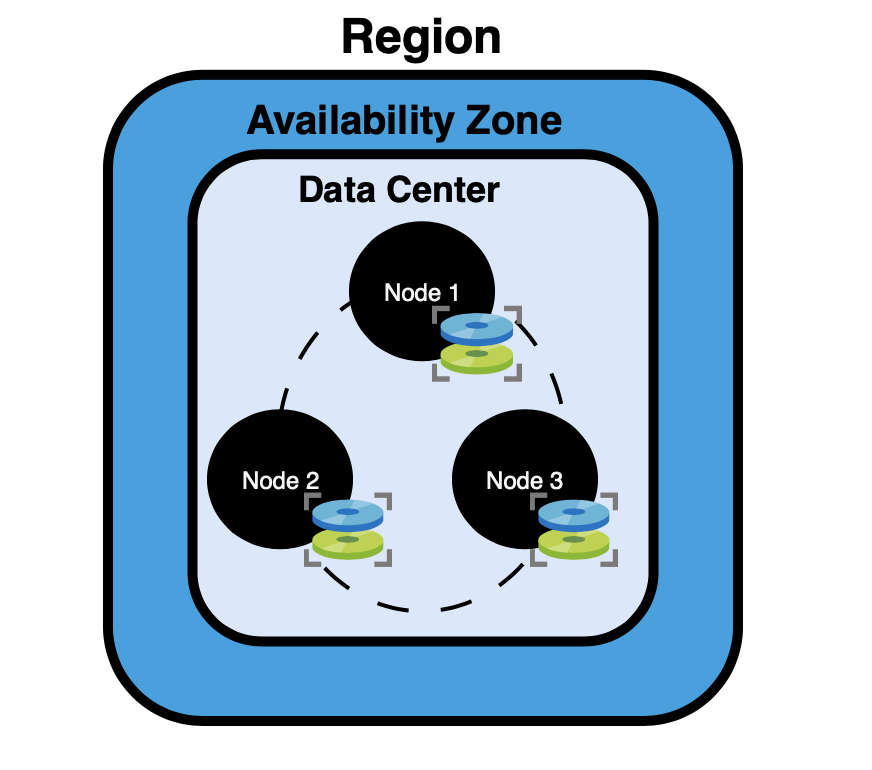
Inside a zone is a data center, and inside the data center are nodes. A node is a server.
All the nodes working together form a cluster, which is your Cassandra database.
If your cluster has three nodes:
- Each node has its own storage and a copy of the data.
- There is no “master” node
- Every node can handle both reads and writes
This is called a peer-to-peer system, where every node is equal.
A simple Example
Here’s an easy way to picture it:
Think of regions as different parts of the ocean. For example, our region could be the Atlantic Ocean, and each Availability Zone is like a harbor within that area. Each harbor is self-sufficient and isolated. If a storm hits one harbor, the others stay safe and unaffected. However, if a massive storm affects the entire Atlantic Ocean, then all the harbors or Availability Zones in that region will be impacted.
If your Cassandra has three ships (nodes):
- Each ship has its own cargo hold (storage)
- There is no admiral or flagship (master node)
- Every ship has a copy of the map (the data)
- Every ship can handle any request
A SQL Server database is like a ship with one captain giving all the orders. If the captain is unavailable, the ship has to wait for a new one to take charge.
Cassandra is like a fleet of ships, where every ship has its own captain. They all know the route and constantly talk to each other. If one ship had engine trouble, the rest of the fleet would keep going. You can even remove a ship, rebuild it, or add a new one if needed.
That’s the power of Cassandra. There is no single point of failure, which is why it is highly available and reliable.
How It Works
If there’s no master, you might wonder how Cassandra keeps everything in sync. It uses two key ideas:
The Coordinator
When you send a query to any node, that node becomes the coordinator for that request. Its job is temporary to figure out which node or nodes should store or retrieve the data, make it happen, and then send the result back to you. Think of it like a short-term project manager handling your request from start to finish.
Gossip
Cassandra nodes constantly talk to each other using a protocol called Gossip. Every second, each node exchanges information with other nodes in the cluster. They share updates like, “I’m online,” “Node 3 looks down,” or “Here’s the latest status.” This constant conversation keeps all nodes aware of what’s happening without needing a central boss.
How Data Is Organized in Cassandra
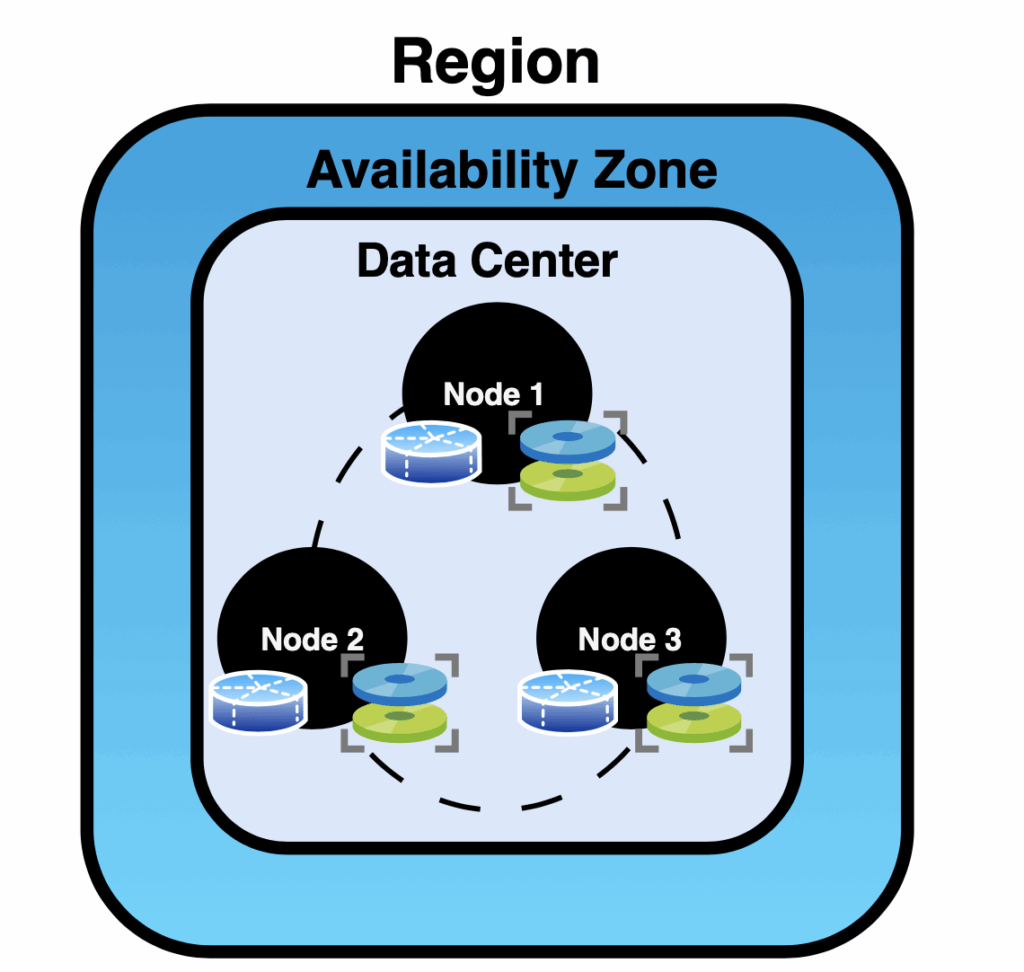
- Region – A geographical area, such as East US or Europe.
- Availability Zone – A distinct location within a region.
- Data Center – A physical facility that contains the nodes.
- Node – An individual server responsible for storing data and processing requests.
- Storage – The local disk space each node uses to store its portion of the data.
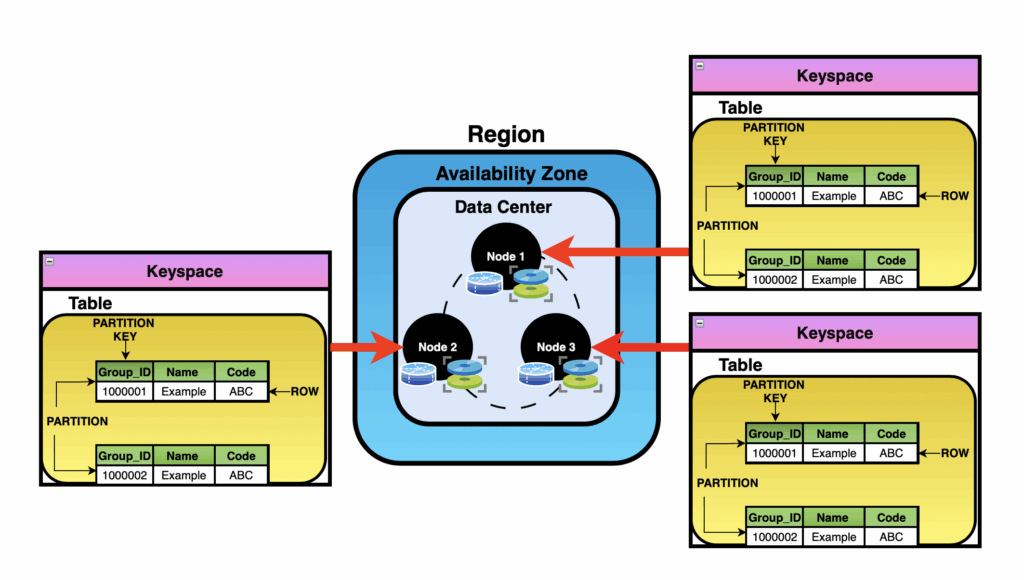
- Keyspace – The top-level container for your data. In SQL terms, this is similar to a database.
- Table – A collection of data within a keyspace, similar to a table in SQL Server.
- Partition – Data grouped by a partition key. All rows with the same key are stored together on a node, which makes lookups extremely fast.
- Row – A single record within a partition.
- Cell (Column) – A specific value within a row. Each row can contain one or more cells.
- Data – The actual stored values inside each cell.
Example Cluster Setup
Here’s a simple 3-node Cassandra cluster setup:
- 1 Region
- 1 Availability Zone
- 3 Nodes
- 1 Keyspace
- Partitioned by:
GROUP_ID
Each of the three nodes has its own storage and a replicated copy of the data.
The data is replicated three times, providing fault tolerance and availability.
If you’re just getting started, I hope this makes you feel a little less intimidated and a little more confident as you begin your Cassandra journey.
Leave a Reply