

Recently, I thought a database query in a plan was straightforward. It looked innocent until I noticed strange behavior. The deeper I dug, the more I realized many people might be running into the same issue with ORM queries.
I’m one of those people who can’t just look at code and move on. I need to go home, spin up a similar setup on my own server, create a database, insert some data, and figure out the reason behind it all.
I didn’t just want to know why SQL Server was unhappy. I wanted to see what was really happening. So, I built a small Java app from scratch in IntelliJ using Hibernate (code will be on Git later).
How many work with ORM (Object-Relational Mapping) code every day, fighting random CPU spikes while trying to keep those AWS or Azure bills under control? If that sounds familiar, this blog might be useful.
The Simple Setup and Query
Here’s the query I started with, a simple SELECT joining two tables from my pretend dog grooming business called DogGroomer, with Pets and Customers. I needed information about the dogs and their grooming needs, searching by the customer’s last name.
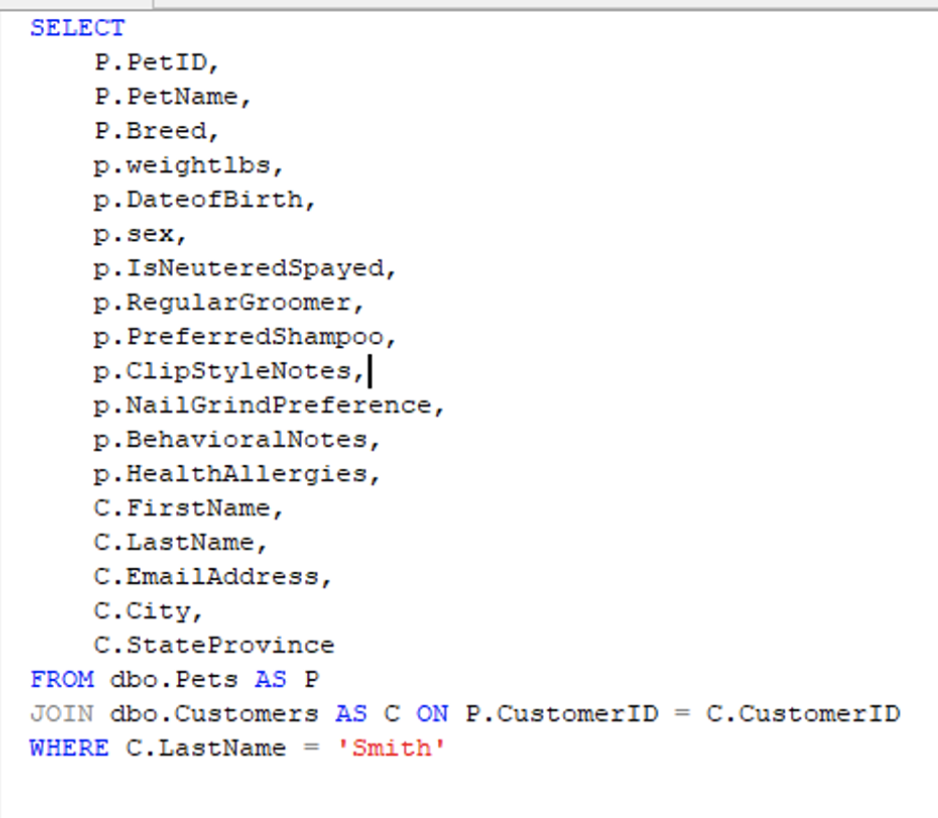
I loaded the database with 200,000 rows in Pets and 10,000 in Customers on my 32-core home server with SSD storage.
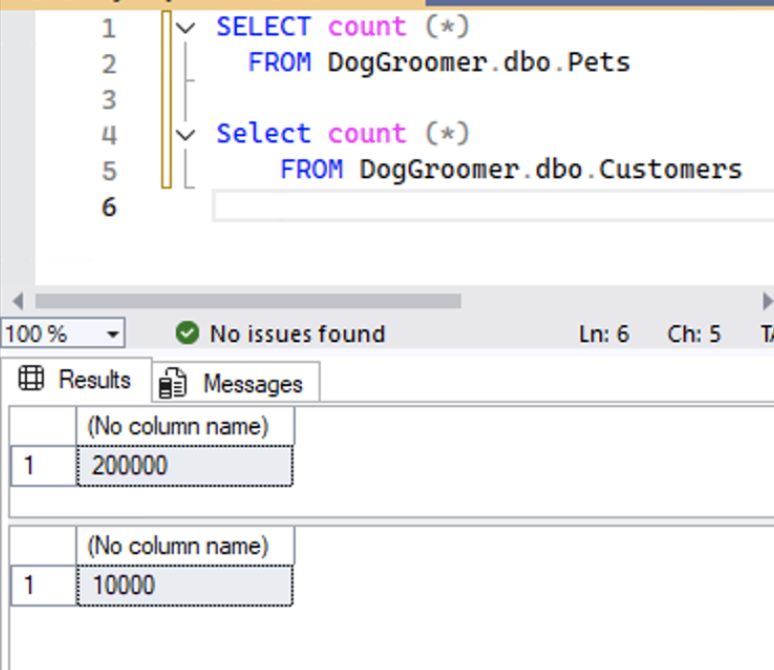
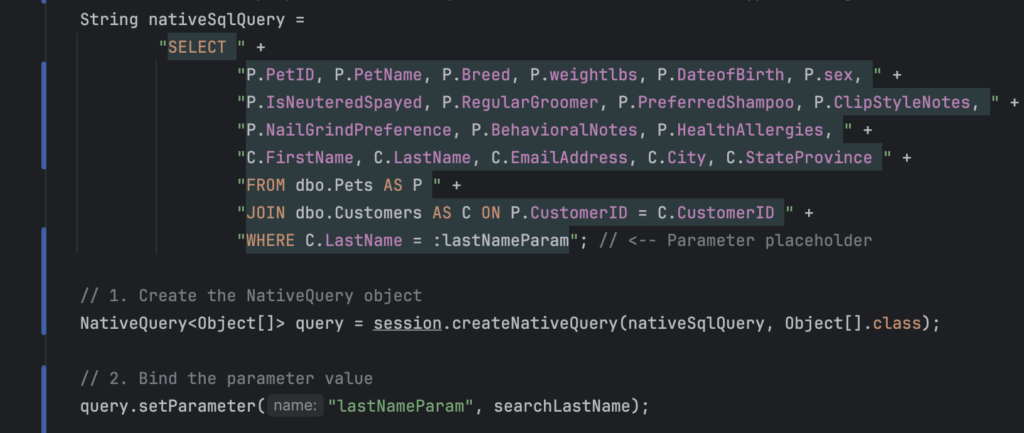
In hibernate it was basic, just with parameters to make it realistic.
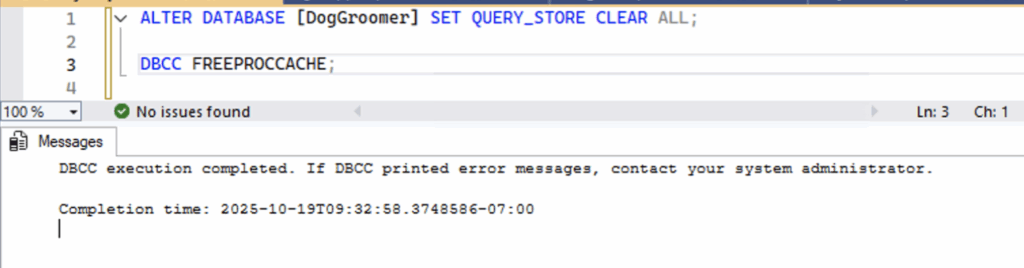
Before running it, I cleared the SQL Server Query Store and cache to get a clean start. (Don’t do this in production!)
Then I ran the Hibernate code a few times and checked the execution plan.
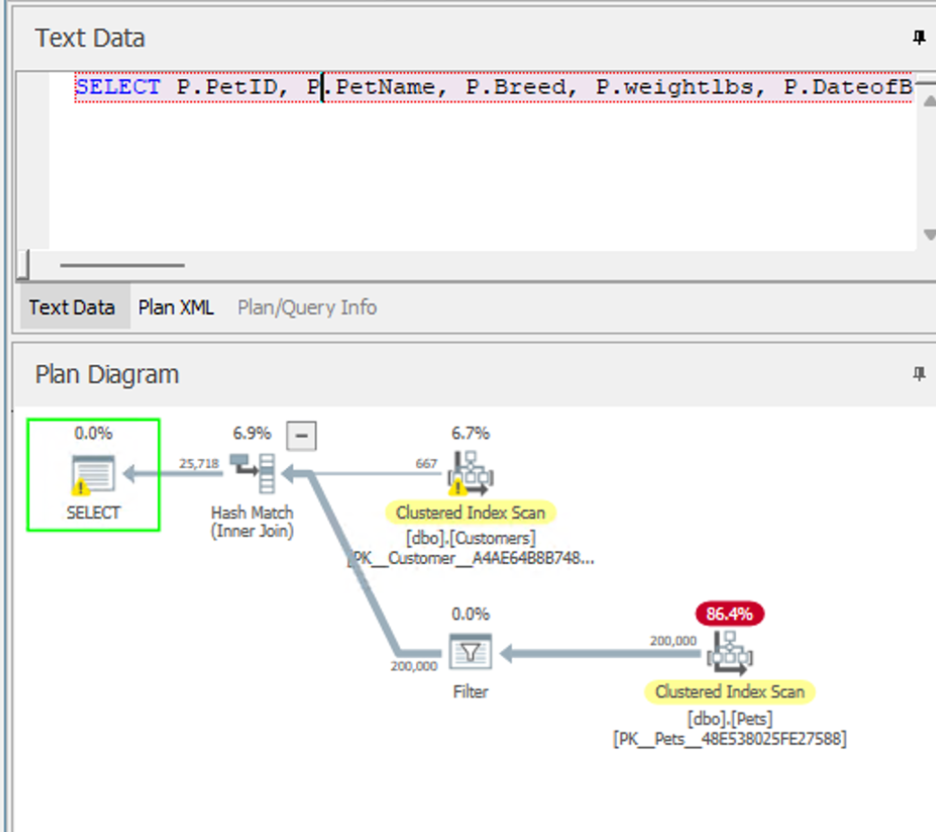
The Seductive Index Suggestion
SQL Server said:
“Hey Amy, add this index!”
It claimed it would improve the query cost by 90.9175%
/*
Missing Index Details from SQLQuery1.sql BLAH BLAH DogGroomer (BLAHBLAH (79))
The Query Processor estimates that implementing the following index could improve the query cost by 90.9175%.
*/
/*
USE [DogGroomer]
GO
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [dbo].[Pets] ([CustomerID])
INCLUDE ([PetName],[Breed],[WeightLbs],[DateOfBirth],[Sex],[IsNeuteredSpayed],[RegularGroomer],[PreferredShampoo],[ClipStyleNotes],[NailGrindPreference],[BehavioralNotes],[HealthAllergies])
GO
*/Tempting, right? Just create the index and call it a day.
Except it wasn’t. This was a trap.
The Index Trap of Trading One Problem for Three
SQL Server suggested a wide covering index that included almost every column the query touched. It sounded great, but all I really did was trade one expensive problem for three new ones.
1. The Storage Cost
Indexes take up space. A large covering index can easily double your table size, which means higher cloud storage costs.
A covering index stores copies of the columns it includes in a B-tree. If your table has 16 columns and your query uses 12, the index might include all 12. This means those 12 columns are duplicated on top of the base table.
Example: 50 GB table → 50 GB covering index → 100 GB total.
The Cloud Cost Angle
In AWS RDS or Azure SQL, storage isn’t just disk. Costs multiply with redundancy, snapshots, backups, and IOPS.
That doubles your storage costs and increases backup time, maintenance, and I/O load on that one table. You might even get bumped into a higher performance tier because of it.
So even though SQL said “add this index,” it quietly added that cost to your cloud bill too.
When It’s Worth It (and When It’s Not)
Covering indexes are great for read-heavy systems when they’re narrowly targeted, maybe two or three columns for a hot query. I would not add 12 columns.
But when they’re created reactively because “SQL told me to add it,” they often balloon in size. People include every column SQL suggests, even ones the query barely touches.
And honestly, SQL doesn’t always suggest the best index. It just suggests an index.
That’s how you end up with a massive index that basically duplicates the entire table.
2. Performance
Every time you insert, update, or delete a record, SQL Server has to update both the table and all related indexes. Those small hits add up.
That one index might make a single query faster, but it can slow down everything else.
3. Maintenance
Over time, you end up with a bunch of one-off indexes created to fix single query issues. The database becomes cluttered, harder to maintain, and more expensive to back up.
Sometimes adding an index doesn’t solve the problem. It just moves the cost somewhere else and adds technical debt.
Testing the Index
I added the index I called “THE WHALE,” then ran it again. Would you be surprised to know it actually ran longer?
Before the WHALE was added:
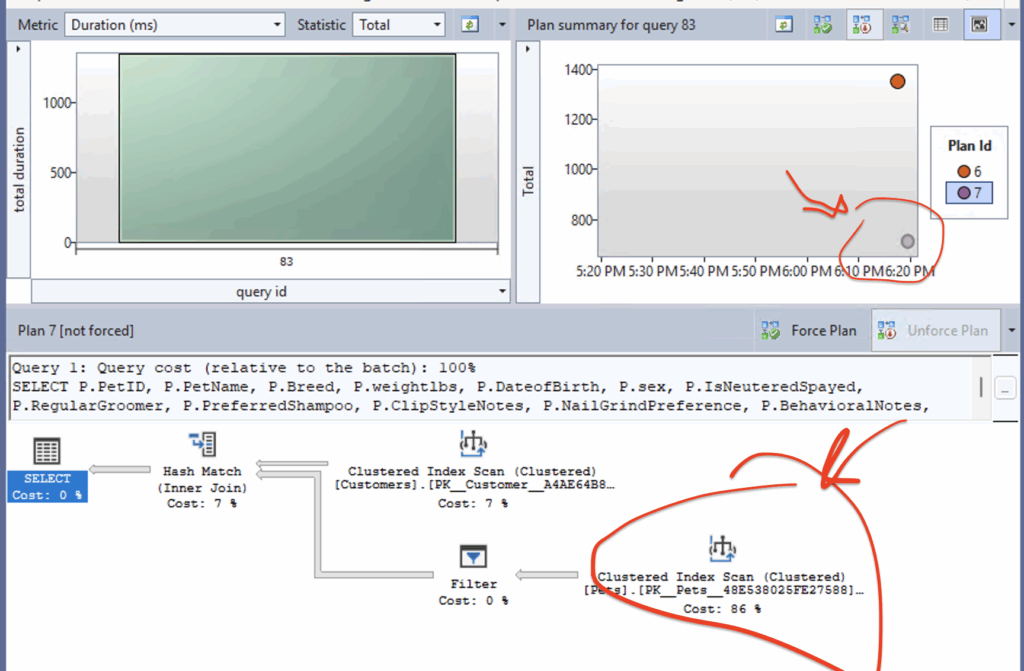
After the WHALE was added:
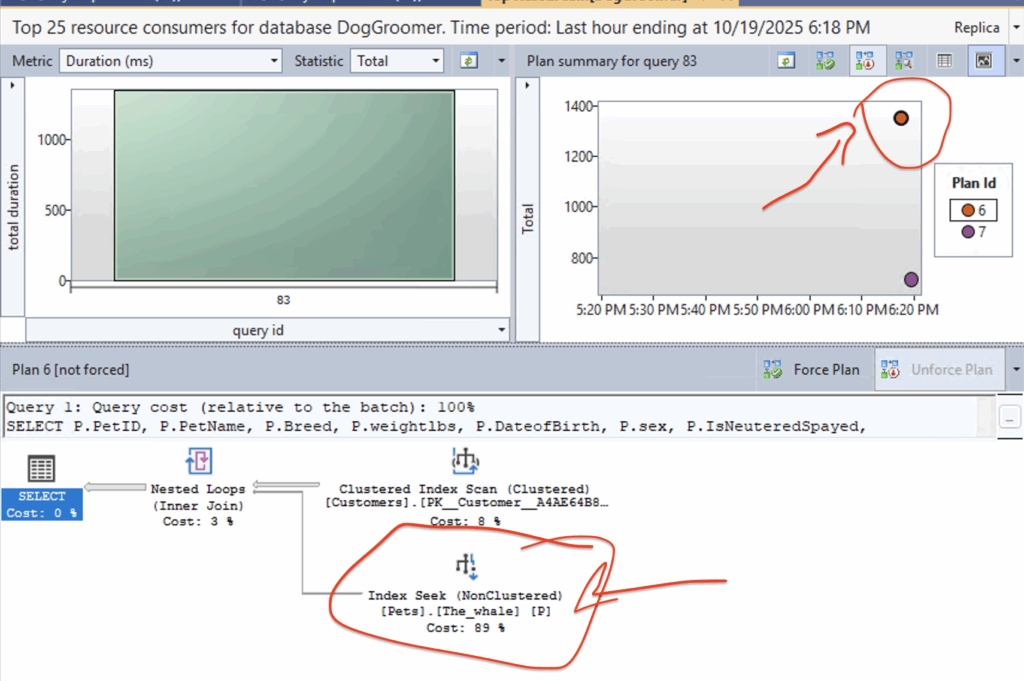
Many people would immediately say, “Show me logical reads, update statistics, clear the cache, and add more indexes.”
But hold on.
First, I never rely solely on duration. When someone tells me, “It ran faster,” I immediately want to lose my mind.

Duration alone doesn’t tell the full story.
The real question is: what do we actually mean when we say, “This query is faster”?
Duration is just the symptom. The real tuning starts with the cause. Are we aiming for less CPU, better execution plans, cheaper operators, or lower I/O? Those are the questions I ask. But even if I answer them, it still might not solve the real problem. That index is often just a red herring.
The Hidden Conversion Problem
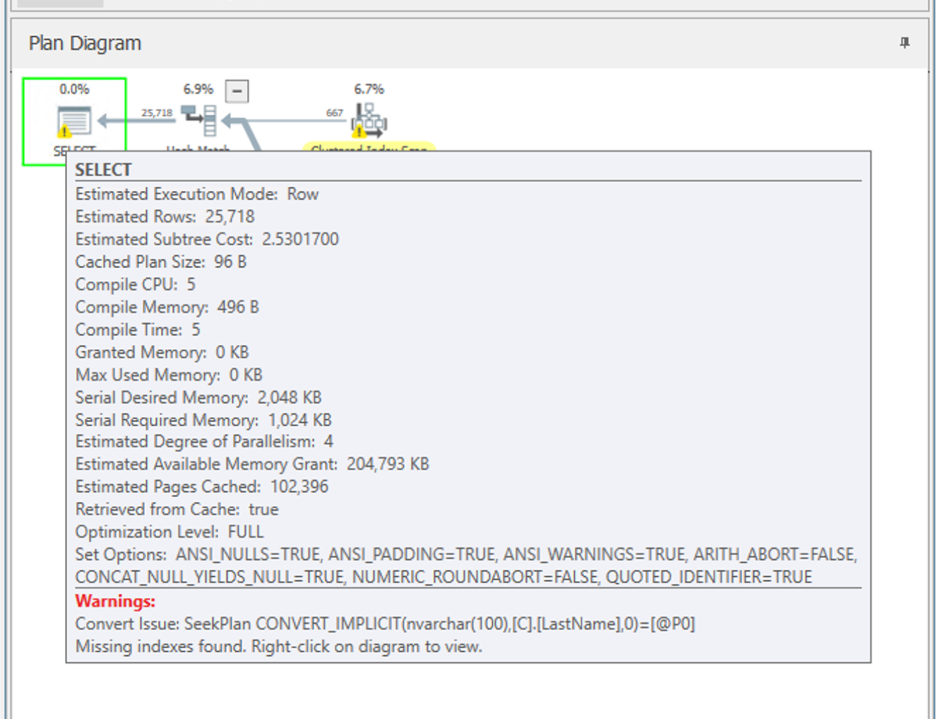
Looking at the plan, you might wonder, “Why is SQL converting VARCHAR to NVARCHAR?”
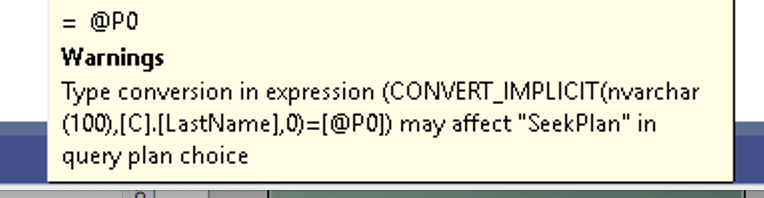
The code and the schema didn’t look mismatched, but SQL Server was still doing it.
The culprit? Hibernate.
Why Hibernate Does This
Hibernate sends parameters as NVARCHAR by default because Java represents strings in UTF-16. The JDBC driver passes that data as NVARCHAR to prevent character loss. It’s a safe default, but it comes with a performance price.
If your database column is VARCHAR but Hibernate sends NVARCHAR, SQL Server can’t use the index efficiently. NVARCHAR has a higher data type precedence, so SQL converts the entire column before comparing. That’s extra CPU, extra work for the SQL Server.
VARCHAR vs NVARCHAR
ORMs like Hibernate and Entity Framework are great for productivity, but they hide costly details.
Most ORMs default to NVARCHAR because it supports Unicode and every possible language.
That’s fine if you need it. But if your data is mostly English, VARCHAR is cheaper and faster.
VARCHAR = 1 byte per character
NVARCHAR = 2 bytes per character
So when your ORM sends NVARCHAR to a VARCHAR column, SQL converts the column, invalidating the index and forcing a scan.
Fixing It
There are several ways to fix this, but the real fix is good design, something we all tend to push under the rug until it costs us.
- Use Stored Procedures for more flexibility and reliabilty. Flexibility, reliability, and cost control are often more important than convenience in the long run. Especially if you don’t just want your operations people adding a ton of indexes everywhere.
- Check your ORM configuration and explicitly tell it to use VARCHAR when Unicode isn’t needed. Test carefully because sometimes it doesn’t even work as expected, if at all.
- Set the connection string to avoid defaulting to NVARCHAR, but understand the risks before you do. The default exists for a reason. I have read it prevents corruption but not sure how true that is.
- If you actually need Unicode, then change the column type. Otherwise, don’t. This is RARELY the solution.
These small design decisions, like datatypes, defaults, and ORM mappings, are the pitfalls of performance and cost.
Testing the Hibernate Change Without the Index
You’re probably wondering, did I ever test the VARCHAR change?
Yes. I changed the Hibernate code in IntelliJ to default to VARCHAR in the hibernate.cfg.xml file and ran it again.
DO NOT DO THIS WITHOUT DOING YOUR OWN RESEARCH!
<property name="hibernate.connection.url">
jdbc:sqlserver://MYIP;
databaseName=DogGroomer;
sendStringParametersAsUnicode=false; encrypt=true;
trustServerCertificate=true;
</property>
Guess what? It worked.
CPU dropped. The query ran without the conversion error in the plan and I didn’t add a single index.
I cleared my cache and Query Store between runs (again, don’t do this in production) just to be sure. The CPU compile time dropped from 8 to 4, meaning SQL Server spent less effort generating the plan and less CPU during execution.
Summary
Adding an index should always be the last resort. They’re expensive and often added without understanding the real issue. It’s like buying new rims for a car that has flat tires. Fix the flat tires first.
Yes, the plan changed a bit. Scans are still there, but CPU is lower and compile time dropped by half.
If fixing the conversion makes the query more efficient, you might not need a new index. And if you do, it’s probably not the 12-column monster SQL suggests. Adding one might give a small boost but increase costs and maintenance.
ORMs make it easy to write queries without thinking about what SQL Server is actually doing. But that convenience can hide costly problems like type conversions, implicit casts, or bad parameterization. Before adding an index, check how the ORM is sending data to SQL. Sometimes just fixing the ORM layer saves more CPU and storage than any index ever will.
The real takeaway: don’t chase every scan and don’t blindly trust index suggestions. They’re often wrong.
As cloud costs rise, storage and indexing are becoming just as important as CPU. Everyone watches CPU and reads, but storage and indexes quietly drain your budget.
Performance tuning is like peeling an onion. Start with the big issues and work your way down. It might make you cry, but the lesson is worth it. Sprinkling indexes everywhere won’t always fix the problem, and ORM queries might not even use them.
Give SQL Server what it needs to make better decisions, and you’ll spend less time fighting fires later.
Leave a Reply